
Gimmal Discover is scalable to any organization, regardless of the overall data size. However, steps can be taken to increase throughput. If there are no concerns with the length of time a Classification/Data Governance Policy and/or eDiscovery Search can take, a company with thousands of Data Targets does not need to deploy more than one Connector. However, if you want to decrease the amount of time that a Policy/Search takes, you do have some very viable options. This Tech Tip will cover your choices and it is recommended you leverage as many of these as you can.
Increase the # of Threads
For any of the Data Source agents, you have the ability to increase the # of Threads. Since each thread allows for the simultaneous processing of a Data Target, the more threads you have, the faster the Policy/Search will run. Though the maximum # of Threads is 50, it is recommended to never set it that high. Instead, the highest recommended # of Threads is 10. To set the # of Threads per Data Source, select the Connector and click More | Connector Settings, as seen below:
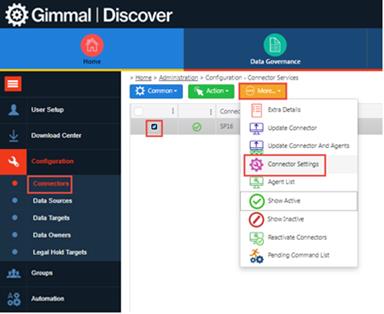
Click on any Data Source tab, and you will see the ‘Max Policy Thread Count’, as seen below:
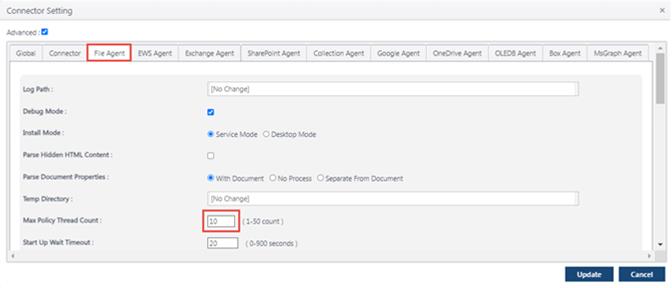
Enter the value and click ‘Update’. Since Gimmal Discover is a hybrid SaaS solution, the new # of Threads will not take effect immediately. Again, caution is advised when assigning more than 10 threads, because there could very well be a point of diminishing return by having too many threads.
Note: The default # of Threads is 3.
Increase the # of Connectors
Since Gimmal Discover does not license the by the # of Connectors, you can deploy as many Connectors as you like. Once the new Connector has been deployed, you can then assign the Data Targets to the new Connector, as seen below:
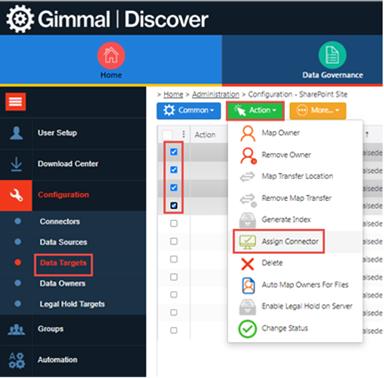
Select the Data Targets and click Actions | Assign Connector, which will display a list of Connectors. Select the Connector and click ‘Save’. This will then permanently assign the Connector to the Data Target. So any Policy/Search that is run, the assigned Connector is the one that processes each Data Target. A Script can be created and scheduled when needing to dynamically assign the Connectors. This is useful when ensuring the Data Targets are evenly distributed across the Connectors. Contact support@gimmal.com for details.
Note: Only one Connector can be deployed per server/VM. So if you want five Connectors, you will need five servers/VMs.
Resize your Windows File Path Data Targets
The Data Targets for Windows File Paths are unique, because they can be created at any subfolder level. This means that you have the ability to control the Data Targets, For instance, if you have a UNC path (e.g., \\MyData\Departments) that is 1 TB, you could create a Data Target for that specific UNC path. But that means that only one thread will be used to process all 1 TB of the path. But if there are 10 subfolders below the \\MyData\Departments folder, you could configure the Data Target Search to create a Data Target for each subfolder. In this scenario, each of the 10 subfolders would be a Data Target. If 10 threads were assigned, all of the Data Targets could be processed simultaneously, thus increasing the throughput by 10x.
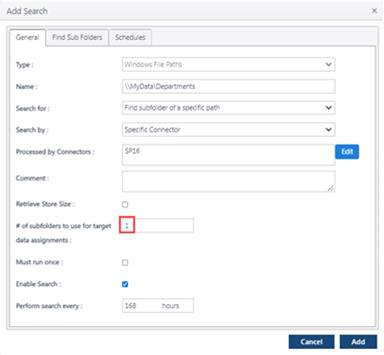
Enter 1 in ‘# of subfolders to use for target data assignments.
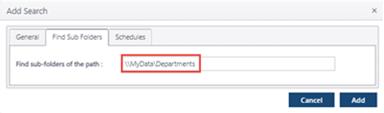
Enter the parent UNC path.
When the Data Target Search runs, a Data Target will be created for every subfolder within the parent UNC path.
Index your Windows File Paths
To expedite processing of the content (not metadata) of the Windows File Path Data Targets, it is recommended that you index the Windows File Path using Gimmal Discover, as seen below:
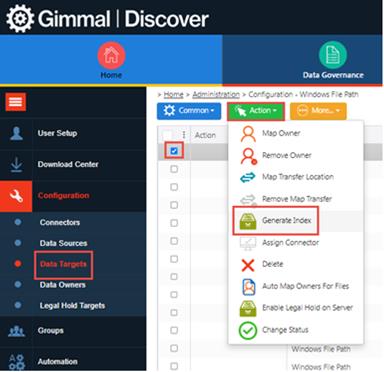
Once indexed, content processing by a Policy/Search will be a great deal faster.
Leverage the Server-side filtering
Using the ‘Fast Search’ (Classification/Data Governance) and/or the ‘Quick Search’ (eDiscovery) for EWS Archives/Mailboxes will leverage the index that Exchange-Online and Exchange 2016/2019 maintains. This will expedite processing when searching content, but also allows parameters to be passed that returns a matching subset of messages. For instance, using the ‘Fast Search’ within an EWS Mailbox Workflow will allow you to filter the messages using dates, types, classes, etc. When used processing a folder, instead of having to interrogate the metadata for each item, Exchange will filter the items so that it returns only the ones matching the parameters. For instance, if there are only 100 messages within a specific data range in a folder containing 10,000 messages, Exchange will only return the 100 messages, thus saving time.
In the example below, the ‘Fast Search’ criteria has both the type of messages and a search expression.
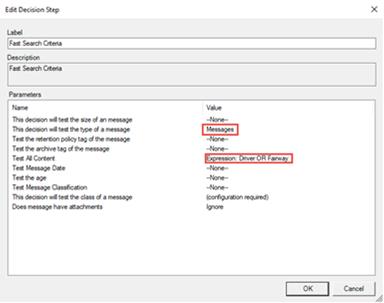
Exchange will only return the items that are of type ‘Message’ and match the specified search expression.
Leverage Classification
Classifying provides a proactive method of tagging a data item based upon matching metadata and/or content. The tag can then be referenced by both Data Governance and eDiscovery to only process the data items that match the desired tag(s), as seen below:
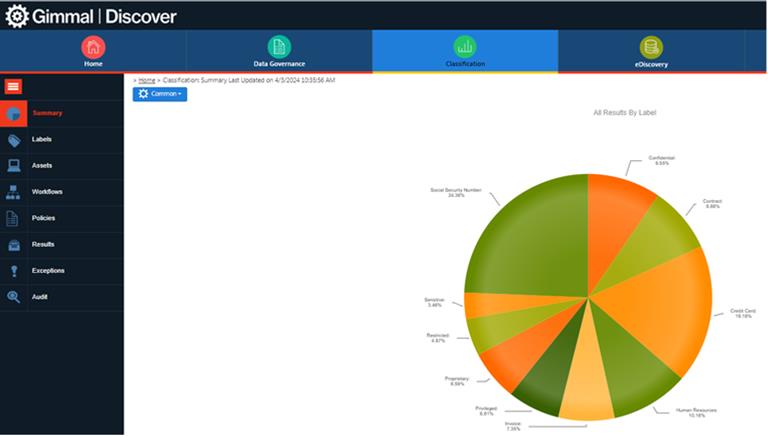
In this example, if a Policy/Search only wants to process the data items tagged with a specific label, instead of processing the entire set of data, you could focus a specific label. If a label has only been applied to 5% of the data, the Policy/Search will run 20x faster, since only the data items with that specific label need to be processed.
Please reach out to the Gimmal support team at support@gimmal.com with any questions.
First Published April, 2024